
AI스타트업으로 GPU의 사용은 필수적이다. 많은 스타트업들이 나름의 기준으로 GPU를 도입하고 사용을 하고 있습니다. 그 형태는 클라우드 일수도 있으며 OnPremise일수도 있으며, 하이브리드로 구성도 도입이 가능합다. 우리가 GPU를 도입하는데 진행하였던 의사결정, 모델선정 기준에 대하여 공유를 함으로 많은 신규 도입 의사를 검토중인 엔지니어에게 도움이 되었으면 합니다.
본 내용은 당시 도입 시점의 데이터를 기반으로 하고 있음을 미리 양지하기 바랍니다.
도입 배경
2023년 06월. 현재의 인핸스에 Machine Learning Engineer로 합류를 하게 되었습니다. 당시 본격적으로 AI를 기반으로 한 서비스의 도입과 확장을 시작하려는 시점이었습니다. 필요한 서비스는 우선 상용 AI를 기반으로 범용모델에 기반한 서비스 구성이 대부분이었습니다. 세분화된 모델, 상용 AI로 처리가 불가능한 모델의 도입, 그리고 향후 내재화 특성 모델에 대한 도입을 위하여 GPU 도입에 대한 필요성을 지속적으로 제기하였습니다.
2023년 10월. 본격적으로 GPU 도입추진을 위하여 CEO, CTO, 그리고 본인으로 구성된 제 1회 GPU 도입 추진 위원회를 구성하였다. 당시의 도입 시점에서 제기되는 필요성은 아래와 같습니다.
도입 필요성
당시 2023년 하반기부터 사내 서비스 및 기능 확장에 따른 LLM모델의 사용성이 증대되고 있으며, 이로 인한 상용모델의 사용량이 급증하였습니다. 당시 서비스의 사용량을 고려한다면, 복합적인 이유로 GPU의 필요성이 대두되고 있었습니다.
- 상용AI모델인 GPT3, GPT4의 성능은 물론 월등하나, 일정 field 혹은 domain 에 특화된 모델이 아닌 범용목적의 모델입니다. 즉, 이로 인하여 우리가 진행하는 특정 domain 에 적용하거나 특정 목적에 알맞은 결과를 도출하기 위해서는 추가적인 작업이 필요합니다.
- 이러한 모든 활동은 상용서비스의 특성상, cost에 항상 영향을 받고 있습니다.
학습에 소요되는 비용과 이를 기반으로 실제 서비스를 제공하는 경우의 cost에 대한 고려가 필요합니다.
- 이러한 모든 활동은 상용서비스의 특성상, cost에 항상 영향을 받고 있습니다.

(REF : https://openai.com/index/gpt-3-5-turbo-fine-tuning-and-api-updates/)
- 상용모델에 의존적인 서비스를 구성하는 경우, 해당 서비스에 종속적인 시스템으로 구성할수밖에 없는 취약점이 발생 합니다.
- 항상 대안모델을 고려한 Plan-B는 준비가 되어야 하며, 이에 대한 대안으로는 Lama2와 같은 상업적 이용이 가능 모델의 도입 및 운용 입니다.
이와같은 필요성으로 대안적 LLM 모델에 대한 선행적 연구 및 학습, 그리고 도입검토와 같은 일련의 행위를 위한 GPU의 필요성이 더욱 증대하였습니다.
요구사항
우선 어떠한 수준의 모델에 대한 학습과, 향후 모델의 개발추이를 고려하여 어느정도의 요구사항이 필요한지 당시 시점의 모델에 대한 list-up을 기반으로 구성하였습니다.

(ref : https://encord.com/blog/llama2-explained/)
위 benchmark의 결과를 기준으로 아래에 대한 machine의 spec에 대한 기준을 성립하였습니다.
- 연산속도 (FP32 Flops) 보다는 VRAM을 기준으로 Moel Parameter의 loading을 우선합니다.
- 대상 기준은 LLM 70B + @모델의 Fine-tunning을 기준으로 최소 VRAM은 140GB + @로 진행합니다.
요구사항 분석 근거
모델의 성능을 기반하여 최소한의 도입 기준으로 결정한 분석근거는 아래와 같습니다.
대상으로 삼고있는 LLMA2 70B 모델의 경우, LoRA 기반의 Fine-tunning을 진행한 경우, 아래와 같은 reference를 보유하고 있습니다.

즉, 대상으로 진행을 하는 70B 모델의 경우 입력 token size에 영향을 받지만 full parameter까지 학습이 가능하고, Paramter를 줄여 학습을 진행하는 LoRA를 적용하면 일정 길이의 context에 대한 학습도 가능한 수준 요구 대상으로 선정하였습니다.
위 기준을 바탕으로 학습용 GPU machine과 Inference GPU machine을 분할하여 도입 타당성 검토를 진행하였습니다.
도입 검토
당시 사내에는 두가지 선택지가 있었다. 첫번째는 클라우드 기반 GPU 서비스 구성이며, 다른 하나는 OnPremise GPU 도입이었다. 아래는 당시 진행하였던 도입 검토 대상과 가격입니다.
Cloud / A사
VRAM 320GB, A100 8 EA
권장 spec으로 선정할수 있는 총 VRAM 320GB, A100 8장이 있는 인스턴스의 비용입니다.
대상 인스턴스는 p4d.24xlarge 입니다.

요금을 진행하는 경우, 1년을 기준으로 하기와 같은 운영비용이 발생합니다
- 시간당 $ 32.77 ( ~= 4만5천원) —> 1일 108만원 / 1달 3240만원 / 1년 3억9400만원1년 약정 $19.22 ( ~=2만7천원) —> 1일 65만원 / 1달 1950만원 / 1년 2억3700만원
VRAM 64GB, V100 8 EA
LLAMA-2 70B 모델 대신 LLAMA-2 7B 모델 도입을 결정하는 경우, 최소 Spec으로 선정할수 있는 인스턴스의 비용이다. 대상은 p3dn.24xlarge 입니다.

- 시간당 $12.24 (~= 1만6천) —> 1일 38만4원 / 1달 1152만원 / 1년 1억4천만원1년 약정 $7.96 (~= 1만원) —> 1일 24만원 / 1달 702만원 / 1년 8400만
학습이 아닌 Inference의 대응을 위한 CPU 서버 기반의 serving도 검토를 진행하였으나응답속도가 서비스 품질의 저하를 발생하므로 예외로 하였습니다.
Cloud / B사
비슷한 성능의 인스턴스를 보유한 B사의 운영요금에 대한 비교도 함께 진행을 하였습니다.


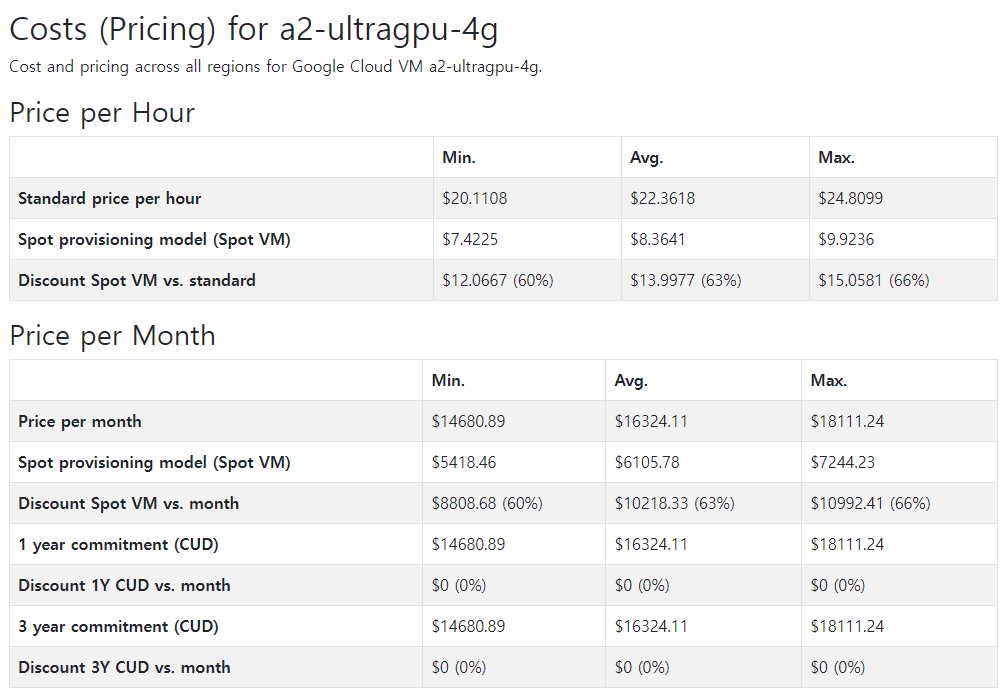
시간당 요금은 더 저렴한 부분은 있으나, 여전히 전체적인 금액은 연간 운영비용으로 2억원이 넘어가는 수준이었습니다.
OnPremise / AMD
AMD의 학습용 GPU인 AMD MI-210의 경우, 아래와 같은 spec을 가지고 있습니다.


해당 GPU의 경우, 당시 검토 도입 시점에 장당 3200만원의 가격대를 형성하였습니다. (지금은 5500만원으로 확인됩니다.)
그러나 AMD 기반의 GPU는 일부 코드 및 소프트웨어의 지원, reference의 부족으로 인한 다른 엔지니어들의 학습시간 소요 등을 고려하여 후순위 선택지로 하였습니다.
OnPremise / Nvidia
사실상 대부분의 Cloud에서 지원하는 GPU는 Nvidia 기반이었습니다. 그리고 이를 기반으로 한다면, 학습과 약간의 inference를 고려하여 도입하는 모델은 A100 80GB 4장을 최소한으로 정할수 있습니다.

NVLink가 지원되는 SXM 폼팩터 모델의 경우, 당시 시점에 대략 근사치로 장당 2300만원 수준으로 추정되었습니다. 즉, GPU 4장의 가격만 1억원이 소요되었습니다.
종합적인 결론을 본다면, Cloud에 비하여 OnPremise의 도입이 각종 비용과 운영적 측면에서의 장점을 가지고 있음을 확인하였으며, OnPremise 도입시 Nvidia 기반으로 진행하는 것으로 결론을 내렸습니다. 특히 당시 Cloud의 경우, Credit을 보유하고 있어도 GPU 서버 인스턴스의 여유분이 없어 사용이 불가능한 경우도 종종 발생하였습니다. 이는 향후 학습 및 모델 inference의 잠재적으로 부정적인 영향을 발생하므로, 더욱 on premise의 GPU machine 도입의 결정적인 근거가 되었습니다.
운영유지비용 분석
전기비용
만일 사내 OnPremise 도입을 진행한다면, 실제 운영비용은 어느정도 인지 예측을 진행하였습니다.
- 최대전력기준, 학습을 한달간 진행한다는 가정하에 전력양 산정
- 현재 계약 조건을 기준으로 산출. (일반용 (갑) I, 저압, 계약전력 10kW)
- GPU에 대한 전기비용만 산정 (서버 / CPU 구동에 대한 비용은 제외)
- 사용전력양 예측기준
- LLM 모델 학습을 기준으로, 하루 18시간씩 20일 사용량을 기준으로 계산
- 학습시간, 학습방법등에 의존하여 전체 비용이 변경됨
- 필요시 70B 모델의 pretrain 가능성을 염두하고 구성하였음.
전체적으로 연간 유지를 위한 전기비용이 항온항습기/에어컨을 포함한 상태에서도 30만원 이하의 요금이 발생할 것으로 예측되었습니다.
이와 같이 OnPremise를 구성하는 경우, IDC 도입과 사내 Micro Data center 구성에 대한 비용분석을 진행하였습니다.
IDC vs 사내 Micro Data center
IDC의 경우, GPU 서버가 고전력 장비의 특성을 가지고 있기 때문에, Rack 2대 분량의 가격을 요구하였습니다. IDC에서는 일반 범용 서버의 경우 3kW의 전력을 기준으로 계산을 하는데, 일반적인 GPU 서버는 해당 전력을 상회하는 4kW 에서 10kW 정도의 전력을 소모합니다. 여기에 추가적으로 Network 운영비용도 함께 포함이 되기에 대략적인 한달 운영비용은 300만원 수준으로 도출이 되었습니다.
만일 사내 전산실을 운영한다면, 초기 구축비용은 매몰비용으로 사라지지만 유지보수 비용에서의 이점이 발생합니다. 또한 Network 역시 사내 network를 바로 사용할수 있기에 산출된 운영비용은 월간 40만원 정도의 금액으로 산출이 되었습니다.
위와 같은 결정을 기반으로 사내 GPU 도입 및 사내 Micro Data Center 구성을 진행하였습니다.
사내 GPU Machine 도입
GPU Machine
도입을 진행하는 목적의 GPU는 아래와 같은 목적을 바탕으로 진행하였습니다.
요구사항
### GPU 견적 요청 시방서
요청사항
- Training 목적의 서버
: 고수준의 inference, 대용량 traffic의 inference목적이 아님.
학습목적 및 약간의 POC 확인용 내부 inference
- Data 처리 및 보관에 대한 Needs는 매우 낮음
CPU : Intel Xeon, 24 Core ( Gold 6248R 수준)
Memeory : GPU VRAM 2X 수준인 512 GB 정도의 RAM size
Storage : NVME SSD, 8TB 수준
- GPU 4장 혹은 8장 지원이 가능한 모델
: 8장의 경우, 실사용 Reference를 보유할것
- 서버 전력소비량에 대한 테크니컬팀 자료 첨부 요청
업체 선정 및 도입
### 업체 선정 기준
1. Top Vendor 인가?
- 다종 server, 구성 및 GPU (고집적) 서버 구축 경험을 보유하고 있는가?
- 구매 요청 이후 최대 4개월 이내 납품이 가능한가?
- 요청 및 구성하는 Server의 Reference를 보유하고 있는가?
2. 기술 Service 지원이 가능한가?
- 2 Yr 이상 Warranty 제공이 가능한가?
- 필요시 Technical Service를 요청할수 있는가?
3. 사내 Needs에 대한 정확한 분석 및 시스템 구성이 가능한가?
- 사내 규모에 알맞은 서버 구성 및 기술상담 지원이 가능한가?
- 요청한 Spec 내에서 가장 적절한 시스템 구성을 해줄수 있는가?
위와같은 조건을 바탕으로 4군데 업체를 통하여 미팅을 진행하였습니다. 업체를 통하여 당시 A100은 도태시점이었으며, H100의 납기일이 4달 이상 소요되는 것으로 전달 받았습니다. 그 대신 신규 모델로 구성된 L40S GPU에 대한 소개를 2군데 업체로부터 전달 받았습니다.
L40S
당시 소개를 받은 L40S는 범용GPU로 A100에 근접한 spec을 가지고 있으면서도 빠르게 2달 이내로 납기가 가능한 모델이었습니다. 전체적으로 A100에 대비하여 메모리 대역폭은 절반 정도 이지만, FP32의 연산속도는 A100 대비 약 3배 이상의 성능을 보여주고 있습니다. 또한, 동작 Power는 A100 대비 80% 수준으로 유지비용에서의 이점도 함께 가지고 있습니다.
다만 L40S의 경우, PCIe Slot이 적용되어 NVLink 대비 동작시 약간의 병목현상이 발생할 가능성도 내포하고 있음을 인지하고 있습니다. 그러나 가격적인 이점과 도입 가능한 시점, 전반적인 범용성을 고려한다면 충분히 A100을 대신할수 있는 성능이기에 L40S 모델을 기반으로한 머신을 도입하기로 결정하였습니다.

GPU 견적 Spec
각 업체별 L40S 모델을 기반으로 최대 8장까지 지원 가능한 machine에 대한 견적비교를 요청하였습니다.
위와 같은 기준을 바탕으로 C사에서 제안한 Machine을 선정하여 도입하였습니다.

사내 Micro Data Center 구축
IDC 대비 사내 Micro Data Center 구축시 월간 약 150만원의 비용감소가 가능합니다. 이를 바탕으로사내 Micro data center 공사를 진행하였습니다.
- GPU Rack 최대 2대까지 도입가능
- 서버는 High-end 머신 1대 혹은 현 수준 머신 2대 도입 가능 수준
- UPS 필요시 도입 가능하도록 배전반 구성
위와 같은 조건으로 SGP 판넬로 구성된 Micro Data Center 구축에 약 1천 5백만원 수준의 비용견적이 발생하였고, 10개월 이상 운영시 매몰비용 이상의 이득이 발생함을 확인하였습니다.
사무실내 별도의 공간을 할당하여 구성하였으며, SGP 판넬로 약 3평 규모의 Micro Data Center 구성을 진행하였습니다. 소모 가능한 전력을 20kW로 상정하여 별도 배전반을 통해 전력을 공급하도록 구성하였으며, 기존의 조명 rail을 이용하여 천정형 tray로 전력을 공급하였습니다.
내부 온도 조절을 위하여 40평 규모의 에어컨을 설치하여 냉방용량 14.5 kW 수준을 구성하였습니다. 이는 현재 구성된 서버의 최대 발열량 3.8 kW를 고려하면 향후 DGX-1과 같은 약 10kW의 고성능 machine에 대한 대응도 가능한 수준으로 구성하였습니다.


사내 Micro Data center 모습. 약 3평 규모
이렇게 도입된 GPU를 기반으로 사내에서는 다양한 연구 및 기술개발, 그리고 일부 모델에 대한 product 수준의 inference를 함께 진행하고 있습니다.
도입 이후
전체적으로 사내 GPU 도입을 진행함으로 연구시 발생하는 비용적인 측면의 감소효과를 제일 크게 체감하게 되었습니다. LLAMA-2 13B 모델을 대상으로 Fine tunning을 진행하였을 때, 클라우드 GPU로 약 7일의 기간을 소요하였으며, 이때 비용이 일간 $1,000 정도, 약 130만원의 비용이 발생하였습니다. 대부분 클라우드 GPU를 사용하는 경우, 학습에 소요되는 시간만 고려를 하나, 실제로는 초기 개발환경 구성, 데이터 연동 등 보이지 않는 비용에 대산 소모도 분명 따져야 합니다. L40S 8장의 GPU를 구성하는 경우, 유지비용이 시간장 전력 소모량 3.2kW를 기준으로 일간 8천원 정도의 비용이 발생하였습니다.
초기 룸 냉각을 위하여 에어컨 비용이 일정부분 소모되었으나, 밀폐가 되어있는 Data Center의 특성상 이후에는 항온항습이 유지되었기 때문에, 지속적인 사용시 내부 온도 유지비용은 오히려 크게 발생하지 않았습니다.
또한 상용모델의 비용 감축을 위하여 내재화 모델에 대한 inference를 구성하여 비용적 측면을 query당 $0.18 수준에서 $.0.01 수준으로 약 90%에 가까운 감소를 구현한 케이스도 있었습니다.
연구적인 측면에서도 비용에 대한 부담이 상대적으로 낮았기에, 비록 소요시간은 H100 machine에 대비하여 다소간 늘어난 부정적인 측면은 있었지만(H100 기준 학습시간 0.5일소요 , L40S 적용시 학습시간 2일 소요) 일부 최적화, 도메인 특화 모델에 대한 내부 연구도 지속적으로 되고있습니다.
만일 도입을 망설이게 된다면 본 블로그 글이 많은 도움이 되었으면 합니다.
감사합니다.
in solving your problems with Enhans!
We'll contact you shortly!